









Dr Zweck began his talk by defining cardiogenic shock (CS) as a heterogenous clinical syndrome with unacceptably high mortality. Despite numerous innovations, in-hospital mortality for CS remains at 30–60%. Dr Zweck proposed that recent clinical trials in CS have been unable to identify superior new treatment strategies due to the heterogeneity of included patients. Current CS classifications, such as the 2019 classification released by the Society for Cardiovascular Angiography and Interventions (SCAI), are primarily derived through expert consensus, instead of being data driven.1
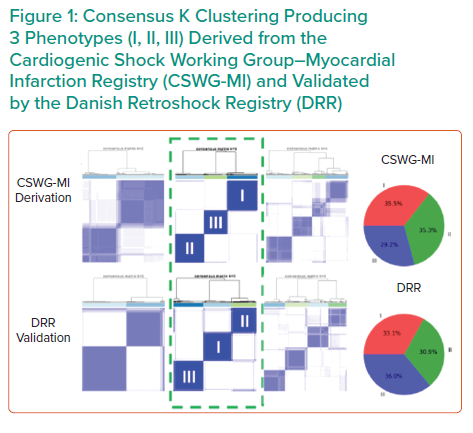
Dr Zweck’s research hypothesis is that a data-driven machine learning analysis could identify distinct phenotypes of CS with clinical applicability. Semi-supervised analysis using consensus K means clustering on clinically relevant mortality-driving variables identified by machine learning was applied to 1,835 CS patients from three international cohorts: the Danish Retroshock Registry (DRR), a two-centre registry of patients in CS after MI; the Cardiogenic Shock Working Group–Myocardial Infarction Registry (CSWG-MI), a US multicentre cohort of patients in CS after MI; and the Cardiogenic Shock Working Group–Heart Failure Registry (CSWG-HF), a US multicentre group of CS patients with acute-on-chronic heart failure. Clusters were derived from the CSWG-MI and cross-validated in the DRR and CSWG-HF.
Clustering techniques with many variables may provide granularity, but often lack generalisation to their applied disease states. Dr Zweck’s research team limited cluster variables to those driving patient mortality to generate a clinically actionable phenotype. Fitting a random forest model to the CSWG-MI cohort identified six variables driving mortality to cluster based on availability, variable orthogonality and predictive importance: glomerular filtration rate (GFR), alanine aminotransferase (ALT), lactate, HCO3, platelets and white blood cell (WBC) count.
Independent consensus clustering of GFR-CKDEPI, ALT, lactase, HCO3, platelets and WBCs to the CSWG-MI and DRR data identified three distinctly different CS clinical profiles (Figure 1). A three-cluster model provided stable or well-defined boundaries in visual representations of the data, as opposed to a two- or four-cluster model for both data cohorts.
Each cluster differs clinically in congestive profiles, haemodynamics, metabolic variables, cardiac function and in-hospital mortality. The key features of each cluster lead to their identification as non-congested CS/phenotype I, cardiorenal CS/phenotype II and cardiometabolic CS/phenotype III. Each phenotype demonstrated distinct in-hospital mortality profiles and applicability to CS patients with heart failure.
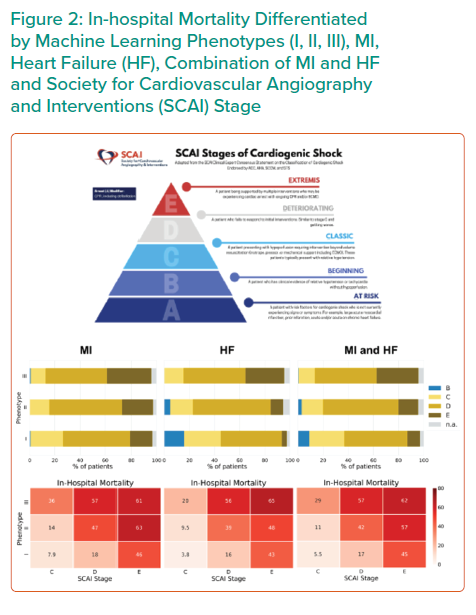
Application of all three CS phenotypes within the SCAI shock classification scheme provides further stratification for mortality (Figure 2). SCAI stage and mortality associated with MI, HF or a combination of both primarily increased with phenotype classification number; non-congested/phenotype I CS patients often exhibit a classic SCAI stage with the least in-hospital mortality, whereas cardiometabolic/phenotype III CS patients exhibit an extreme SCAI stage with the greatest in-hospital mortality.
Dr Zweck concluded that an unbiased machine learning approach identified three distinct clinically applicable phenotypes of cardiogenic shock.2 These phenotypes exhibit different metabolic and haemodynamic profiles, and show a reproducible association with mortality. Each phenotype was classified by their defining features of non-congested shock, cardiorenal shock and cardiometabolic shock, and are compatible with, and enhance, SCAI stages. Future studies may further characterise these phenotypes and apply them in the conception of more targeted clinical trials, instead of a one-size-fits-all solution.